Like always, I'm having a hard time making myself to write in English, even though I know how important it is, especially after OpenEd.
This post is meant to talk about the first Spanish Open Course that I get to offer (actually it's the first one, no matter the language ![]() ), which came from an invitation by University of La Sabana, in Bogotá. They contacted me a few months ago, inviting me to do a course on their master on educational informatics program. I accepted on one condition: It would have to be open.
), which came from an invitation by University of La Sabana, in Bogotá. They contacted me a few months ago, inviting me to do a course on their master on educational informatics program. I accepted on one condition: It would have to be open.
So here I am, a few months later, after thinking a lot about its design and discussing it with a few people (I *really* need to learn about creating/designing in public), and obviously getting ideas from the work of people like David Wiley, Alec Couros, George Siemens & Stephen Downes and Leigh Blackall.
The course already have 14 for-credit participants, and about 20 more participants taking it without certification. We have people from Spain, El Salvador, Mexico, Peru and, obviously, most of the participants are from Colombia.
For now, I'll talk about the technology I'm using, because I think maybe it could be useful to someone, and also it would be great to get feedback on it. There are two things I wanted to achieve with technology: First, I wanted to do something that could be replicated by each participant (which means only non-paid tools and no hosting); second, I wanted to facilitate access to people who are heavy e-mail users. Also, no walled gardens but a public approach (bye bye Moodle), trying to get participants to work on their own personal learning environments throughout the course.
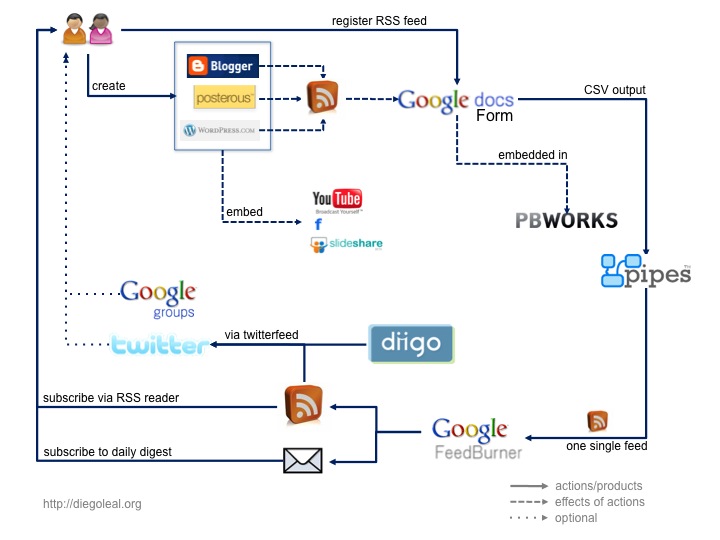
So this is a view of the things I'm using. Detailed info below:

Participants are asked to create a blog on any available service. It is suggested to find for ways to do e-mail publishing, so they don't have to go to any website or use any additional tool.
Once the participant has a blog, she has to register it in the course wiki, which has a Google Docs form embedded. They have to include in their registration the RSS feed for their blog.
The GDocs document is then plugged into Yahoo Pipes via a CSV output. The pipe gets all the feeds and create one single feed, which I'm sending to Feedburner. I'm using Feedburner, actually, to create the possibility of an e-mail subscription, and obviously, to get a little control over subscription statistics.
This way, participants think about RSS aggregators only if they want to. They can have an e-mail subscription, which sends a daily message with a compilation of the posts compiled by the pipe during the previous day.
I'm getting the final RSS feed and I send it to twitter via twitterfeed. There's an user (elrn09) which publishes this feed and also the things compiled in a Diigo group created for the course.
There's also a Google group created, which is not being very popular at the time. I kind of understand this, because participants are not necessarily heavy Internet users, so even creating a blog can seem a daunting task for some of them.
Some interesting thing about this:
- The pipe (a very simple one, actually) can get input from any set of RSS feeds (For example, I thought at some point about asking people to get Google Reader accounts and then sharing the posts they found interesting. I could get all the RSS feeds from those Shared items pages, and change the pipe to find the "most read" items in the course. Of course, this faces the problem of getting valuable items lost if they are not shared enough times. In the end, I decided it would be a new layer of complexity for most participants, so I forgot about it)
- After setting up their blog and subscribing to the feedburner feed, people can go back to use the tools they're used to (I'm guessing e-mail is a weapon of choice for most of the participants), both to publish and consume information from the course.
- I "cloned" the whole set-up for another course I was starting, and it was a reasonably quick process. So it is easily replicable.
Some limitations, and things that I'm still trying to figure out:
- How do I analyze all the data coming out of the course? If I wanted to see the progress/evolution of different participants, what kind of tools should I use? Is it possible to do it with the pipe I have now?
- Feedburner is not flexible enough with the mail subscriptions. I'd like every participant to decide whether she gets a daily or real time notification.
- I can't do something like the CCK09 Daily, where some items get to be commented before reaching the participants. That would be nice.
So far, so good. During the first week, I had to keep looking at the feeds that were registered, because some participants would write their blog URL, not the feed URL. Also, some of them registered feeds from existing blogs, so I had to suggest them to label their posts, in order to retrieve just those entries. To "keep clean" the feed, I had to go every now and then and update the source for the pipe, extending the cell range to include the URLs that had been verified already. Some maintenance work that can't be avoided, I guess.
But after that, everything works perfectly. I guess a OPML file could be generated (and it would help later with analytics, definitely), but so far is something I don't think participants are really needing...
Anyway, I have to confess that I still need to understand much better the way Pipes works. I feel that I'm missing a lot of interesting things that could be done, because of my limited knowledge. However, I'm happy because it looks like it works!
Later, some thoughts about the way the course goes. Definitely, there are a lot of limitations created by our context, and the level of actual use of several technologies that seem common-place in other countries. I'll get to learn a lot about what's possible and what kind of things can be done to make these kind of experiences good learning opportunities.
We'll see how it goes! ![]()