Hace un par de semanas anuncié el inicio de mi primer curso abierto en línea, que ya se encuentra en la mitad de su segunda semana de ejecución.
Como parte de mi reflexión personal sobre el curso, aquí está la descripción de las distintas herramientas que estoy usando, y cómo las estoy articulando. A primera vista puede verse un tanto complicado pero, de veras, duplicarlo es mucho más fácil de lo que parece. Ahora, sin duda habrá un montón de cosas que pueden mejorarse, pero pienso que está bien para un primer intento.
Nunca está de más decir que muchas de estas ideas ya han sido exploradas por otras personas (como David Wiley, Alec Couros, George Siemens & Stephen Downes y Leigh Blackall), y que mi aproximación responde a ciertas condiciones específicas de contexto que inciden en cómo usamos muchas de estas herramientas. La misma solución no es necesariamente válida para distintos grupos.
Entonces, por ahora, me referiré a la tecnología que estoy usando. Hay varias cosas que quise lograr con este diseño: Primero, quise hacer algo que pudiera ser replicado por cada participante (lo cual significa nada de herramientas pagas y nada de hosting propio); segundo, quise facilitar el acceso a usuarios de correo electrónico (que me temo son muchos más que los que usan con frecuencia herramientas de software social). Además, decidí asumir un enfoque público, nada de espacios con muros (así que adiós Moodle y adiós Facebook -porque a pesar de Facebook Connect, es una tragedia obtener mucha de la información de Facebook mediante medios como RSS-), tratando de lograr que los participantes enriquezcan su ambiente personal de aprendizaje a lo largo del curso.
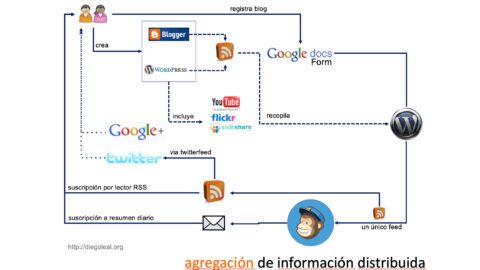
Este es un diagrama de las cosas que estoy usando. Información detallada más abajo:

Cada participante crea un blog en cualquiera de los servicios disponibles. Es sugerido buscar formas de publicar a través de e-mail, de modo que no tengan que ir a ningún sitio web o usar ninguna herramienta adicional. La idea aquí es que desde la publicación, el ejercicio construya sobre las prácticas existentes.
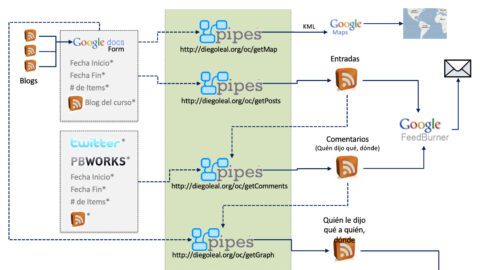
Cuando el participante tiene su blog creado, debe registrarlo en el wiki del curso, que tiene un formulario de Google Docs incrustado. Allí deben registrar el URL del feed RSS del blog.
El documento de GDocs es conectado con Yahoo Pipes a través de la utilidad de exportación en formato CSV de GDocs. El pipe procesa todos los feeds y crea un único feed, que incluye la información producida por todos los participantes. Este feed es enviado a Feedburner, el cual está siendo usado para habilitar la posibilidad de suscripciones por correo electrónico. Obviamente, también me ayuda a hacer seguimiento a las suscripciones.
Así, los participantes tienen que pensar en agregagores RSS sólo si desean hacerlo. Pueden suscribirse por e-mail, recibiendo un mensaje diario con una compilación de los posts compilados durante el día anterior.
El feed RSS final está siend enviado a través de twitterfeed a un usuario de Twitter (elrn09), que publica en "tiempo real" la información contenida en el feed, así como el material compilado en un grupo de Diigo creado para el curso.
También hay un grupo de Google creado, que no está siendo muy popular de momento. Entiendo esto, pues es un espacio adicional y algunos de los participantes no son necesariamente usuarios experimentados de Internet, así que tan sólo la creación de un blog puede parecer una tarea bastante compleja. Ni se diga de monitorear actividad en una cantidad muy grande de espacios en línea, al menos no de momento.
Algunas cosas interesantes sobre esto:
- El pipe (que es bastante simple, de hecho) puede recibir como entrada cualquier conjunto de feeds RSS contenidos en una hoja de cálculo de GDocs (Por ejemplo, pensé en algún momento pedirle a las personas que usaran Google Reader y que compartieran los posts que encontraran importantes. Yo podría tomar todos los feeds de esas páginas de elementos compartidos, y modificar el pipe para encontrar los items más leídos" del curso. Por supuesto, esto tiene un problema, y es que algunos items valiosos pueden quedar perdidos si no son compartidos lo suficiente. Al final, decidí que sería una capa adicional de complejidad para algunos participantes, así que me olvidé de ello).
- Después de configurar su blog y suscribirse al feed de Feedburner, cada persona puede volver a las herramientas a las que está habituada (supongo que el e-mail es una herramienta muy popular entre la mayoría de los participantes), tanto para publciar como para consumir información del curso.
- "Cloné" toda la configuración para otro curso que está por iniciar (GRYC09), y fue un proceso razonablmemente rápido. Así que es algo fácilmente replicable.
Algunas limitaciones, y cosas que estoy tratando de resolver:
- ¿Cómo analizo todos los datos que están siendo generados en el curso? ¿Si quisiera ver el progreso/evolución de diferentes participantes, qué tipo de herramienta debería usar? ¿Es posible hacerlo con el pipe que tengo en este momento?
- Sería ideal que el pipe procesara de manera automática tanto los feeds como las direcciones de páginas que contienen feeds. No logre crear dos ciclos distintos para el mismo pipe...
- Feedburner no es lo bastante flexible con las suscripciones de correo. Me gustaría que cada participante decidiera si prefiere un correo diario a una notificación en tiempo real.
- No puedo hacer algo como lo que se ve en The Daily de CCK09, en donde algunos items son comentados antes de llegar a los participantes. Eso sería simpático.
Hasta ahora, el asunto va bien. Durante la primera semana, tuve que estar pendiente de los feeds que estaban siendo registrados, pues algunos participantes escribían el URL de su blog, no del feed. Además, algunos de los feeds registrados correspondían a blogs existentes, así que tuve que sugerir a estas personas que etiquetaran sus posts, para obtener solamente el feed correspondiente a esas entradas relacionadas con el curso. Para mantener "limpio" el feed final, tuve que actualizar diariamente la fuente del pipe, extendiendo el rango de celdas para incluir solamente los URLs que ya había verificado. Este es trabajo de mantenimiento que no puede evitarse, parece.
Pero después de eso, todo funciona a la perfección. Supongo que podría generar un archivo OPML desde Pipes (y tal eso ayudaría con los análisis),pero hasta ahora es algo que no parece crítico para los participantes.
En todo caso, debo reconocer que aún necesito entender mucho más la forma en la que funciona Pipes. Siento que estoy dejando de hacer muchas cosas interesantes, debido a mi limitado conocimiento. Sin embrago, estoy contento porque parece que funciona!
Más adelante, algunas reflexiones sobre el avance del curso. Definitivamente, hay muchas limitaciones creadas por nuestro contexto, y por el nivel de uso real de muchas de las tecnologías que parecen ser un problema resuelto para algunas personas. Espero aprender acerca de qué es posible y qué tipo de cosas pueden hacerse para que estas experiencias sean buenas oportunidades de aprendizaje.
 A excepción de que se indique lo contrario, este contenido está publicado bajo una licencia Creative Commons.
A excepción de que se indique lo contrario, este contenido está publicado bajo una licencia Creative Commons.