El año pasado, un par de semanas después de que empezó ELRN, escribí un post en el que hablaba acerca de la tecnología que estaba detrás del curso. La idea no es repetir aquí lo mismo que dije allá, así que puede ser una buena idea leer ese post antes de continuar aquí, pues este post corresponde más a una actualización del asunto.
El esquema de tecnología que está detrás del GRYC es, esencialmente, el mismo de ELRN. Por supuesto, ha pasado algún tiempo que me ha permitido aprender un poco más de algunas herramientas, y algunos procesos de mantenimiento ya no me toman tanto tiempo. Pero como hay en GRYC algunas personas que han estado en CCK08 y CCK09, creo prudente explicar un poco qué cosas diferencian a la tecnología de este curso de aquella que Stephen ha puesto al servicio de CCK.
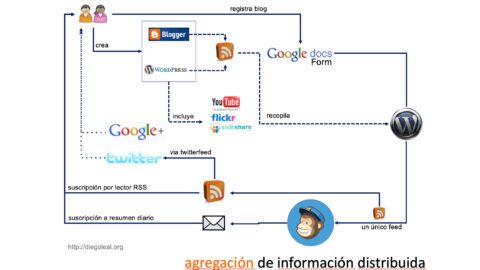
Un primer aspecto a tener en cuenta es que, para el caso de GRYC, todos los servicios que son utilizados para compilar y procesar la información de los participantes son públicos y permiten un uso gratuito. En el caso de CCK, Stephen construyó sobre la funcionalidad de su Grsshopper para facilitar la compilación y republicación de información de los participantes en el curso. Obviamente, esto hace que la de CCK sea una solución más "a la medida" de las necesidades, y que existan cosas interesantes que yo no puedo hacer. No obstante, en la medida en que los servicios que estoy usando son públicos, mi esquema es potencialmente replicable por cualquier persona, y no requiere ningún tipo de alojamiento propio para que funcione. Esa fue una de las intenciones que marcaron mi aproximación a la puesta a punto de la tecnología del curso, que de manera esquemática se ve de la siguiente manera:

Otra clara intención fue ofrecer diversidad de posibilidades de acceso a la información, para que cada persona utilizara aquellos más cercanos a su práctica cotidiana. De allí las diversas opciones de suscripción al contenido del curso (RSS, correo electrónico, Twitter). Lo bueno es que esta complejidad es bastante transparente para los participantes, quienes envían y reciben información usando un blog, un wiki, diigo y su correo electrónico. Eso es lo mínimo que se requiere, así que en realidad no hay una saturación de herramientas (digo yo).
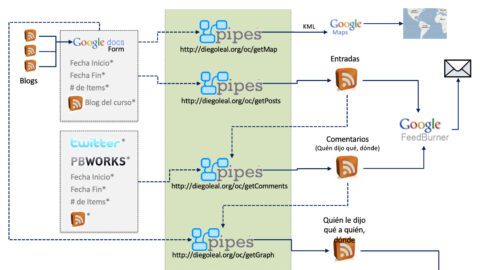
Pero bueno, hora de entrar en materia. En comparación con lo que hice en ELRN, aquí hay algo nuevo, que trata de resolver una pregunta que me hice en ese entonces: ¿Cómo hacer seguimiento a los comentarios que van surgiendo en los blogs? Para resolver esto, empecé usando un pipe que usa la información del formulario de inscripción, y que mediante regex intenta cambiar los feeds registrados para las entradas por los feeds de comentarios de cada blog. Esto es algo limitado pues, por ejemplo, no pude encontrar en wordpress feeds específicos para una categoría determinada, lo cual hace que ese pipe termine compilando todos los comentarios de un blog de wordpress (sin importar que hagan parte o no de posts del curso), y me obliga a tratar de manera individual a otras plataformas... Poco razonable...
Así que hoy encontré otra opción: Usar el feed RSS de entradas de blogs (que es generado por este pipe) como insumo para un nuevo pipe, que procesa cada post e identifica de manera automática el feed de los comentarios correspondiente, para luego obtener el contenido de cada feed y generar un único feed de comentarios. Por lo pronto, parece funcionar, pero algo me dice que van a aparecer problemas eventualmente, por razones que escapan a mi control... Por ejemplo, posterous no cuenta con feeds de comentarios, y algo similar puede ocurrir con otras personas que escriben desde otras plataformas (como joomla o drupal, por ejemplo). Eso quiere decir que habrá comentarios que pueden quedarse por fuera, lo que dificulta un poco hacer otras cosas que tengo en mente...
Lo malo de este enfoque es que no encontré una manera de recuperar el título del post, para incluirlo dentro del título del comentario que genero. Sólo logré obtener el enlace al post, así que no se ve tan bien como yo quisiera. Ni modo.
Eso por un lado. Por otro lado, a partir de las ideas de Tony Hirst, me dije hace un par de días que tal vez podía utilizar la información de ubicación del formulario de inscripción del curso (ciudad y país) para generar de manera automática un mapa con la ubicación de todos los participantes. Con eso en mente, me puse a experimentar con Pipes, en donde tuve que resolver algunos detalles con los que Tony no se encontró.
El módulo Location Extractor de Pipes funciona de manera algo errática, y obviamente en inglés, así que tuve que cambiar "España" por "Spain", por ejemplo, así como algunas tildes en diversas ciudades reportadas por los participantes. Cambié uno por uno los registros de inscripción (lo que me mostró que para la próxima es importante separar el campo "país" del campo "ciudad", lo que no hice en esta ocasión), y al final terminé usando el módulo Location Builder dentro de un iterador para generar los datos de geolocalización.
Además de eso, una pequeña manipulación de texto para incluir junto al nombre de cada persona su ocupación (que también es obtenida en el formulario). Tal como lo demostraba Tony, al final exporté el resultado del pipe en formato KML (Sip, Pipes exporta Keyhole Markup Language) y lo incluí dentro de Google Maps, para lograr un resultado que me dejó MUY contento (note que en México, Argentina y España hay varios globos!):
Entonces, a partir de una hoja de cálculo de Google Docs, estoy generando de manera automática un mapa con la ubicación de todos los participantes del curso, que además se actualiza cuando alguien nuevo se inscribe, sin que yo tenga que intervenir.
Fantástico.
Pensando en las cosas que no funcionan como en CCK, estoy haciendo algunas pruebas para incluir dentro del Diario de GRYC los twits relacionados con el curso, que incluyan la palabra GRYC y estén escritos en español. El asunto se ve prometedor, pero necesito algo más de tiempo para probarlo con el contenido que sea generado por el curso.
Por último, durante ELRN sentí la falta de un mecanismo (adicional al correo electrónico) que me permitiera notificar de asuntos importantes a los participantes. Así que creé un blog en posterous, que también es compilado en el Diario de GRYC. Ahora, para que sea funcional, será necesario que los posts que se escriban allí se publiquen poco antes de la hora de envío programada en Feedburner, para que esos mensajes "administrativos" queden de primeros en el correo.
¿Qué otra cosa? La limpieza y verificación de feeds, y el contacto por correo con todos los inscritos, me llevó alrededor de cinco horas. Pienso que este tiempo podría reducirse sustancialmente si se contara con una sesión presencial dedicada exclusivamente a lo tecnológico, y al aprendizaje de las ideas detrás de RSS. En todo caso, en esta ocasión tenía mucho más claro cómo ajustar cada feed, y de hecho muchos más participantes registraron la información de manera adecuada, en comparación con lo que viví en ELRN.
Uno siempre podría decir que la vida sería más sencilla si simplemente usara un LMS. Y me temo que eso es cierto. No obstante, hay todo un asunto de control de la información por parte de cada participante y de demostración de cómo articular la tecnología para facilitar el seguimiento a un entorno desestructurado y distribuido, que me parece no sólo importante, sino muy interesante. En ese sentido, diría que todo esto es un ejemplo demostrativo, de hecho.
Ejemplo que, de hecho, tiene unas consecuencias MUY interesantes cuando empieza a pensarse en mayor escala. Por ejemplo, ¿qué significaría que un esquema como este fuera implementado a nivel de un programa académico completo? ¿Qué cambia no sólo en términos tecnológicos, sino pedagógicos? Para mi, esa todavía es una atractiva pregunta que, de hecho, lleva a otro nivel mi aproximación a la Educación Abierta, y que parece que voy a tener la oportunidad de explorar en más detalle en el futuro próximo.. ![]()
Por lo pronto, esos son los mayores cambios que he realizado a la tecnología detrás del curso. La mayoría de ellos tras bambalinas, pero buscando facilitar un poco más la eventual replicación de este tipo de esquema. Sin duda, todavía se puede mejorar mucho más en este sentido pero, considerando que esta es apenas mi segunda vez poniendo a prueba todo este esquema, creo que el resultado se vuelve interesante y empieza a mostrar posibilidades con un increíble potencial.
Si usted llegó hasta el final de este post, muchas gracias! Este es uno de esos posts un tanto técnicos y, en consecuencia, algo hostiles para muchos de nosotros. ![]()
 A excepción de que se indique lo contrario, este contenido está publicado bajo una licencia Creative Commons.
A excepción de que se indique lo contrario, este contenido está publicado bajo una licencia Creative Commons.